Introduction to Federated Learning
Federated learning (FL) is a machine learning setting where many clients (e.g., mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g., service provider), while keeping the training data decentralized. It embodies the principles of focused collection and data minimization, and can mitifate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning. This area has received significant interest recently, both from research and applied perspectives. This post will descibe the defining characteristics of federated learning and the majority of the content is based on [1].
The term federated learning was introduced in 2016 by McMahan et al who termed it federated learning as the learning task is solved by a loose federation of participating devices (which are refered to as clients) which are coordinated by a central server. An unbalanced and non-IID data partitioning across a massive number of unreliable devices with limited communication bandwith was introduced as the defining set of challenges.
There are two main variants of federated learning: cross-device and cross-silo. Cross-device focuses on setting with mobile and edge devices while cross-silo focuses on a small federation of relatively reliable clients (e.g., multiple organizations).
| Cross-Silo | Cross-Device | |
|---|---|---|
| Setting | Clients are different organizations (e.g., medical or financial) | Clients are very large number of mobile or IoT devices |
| Data Distribution | Generated locally and remains decentralized | Generated locally and remains decentralized |
| Orchestration | A central orchestration server for training, but never sees raw data | A central orchestration server for training, but never sees raw data |
| Data Availability | All clients almost always available | Only a fraction of clients are available at any one time |
| Distribution Scale | 2 - 100 | up to $10^{10}$ clients |
| Primary Bottleneck | Computation or communication | Communication |
| Addressability | Each client has an unique identifier | Clients cannot be indexed directly |
| Client Statefulness | Stateful | Stateless |
| Client Reliability | Relatively few failures | Highly unreliable |
| Data Parition Axis | Parition is fixed. Horizontal or verical | Parition is fixed |
Standard Training Process
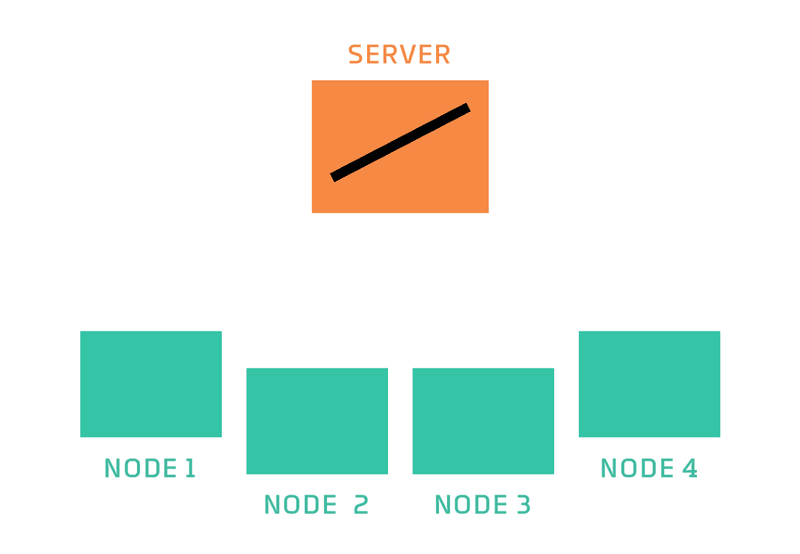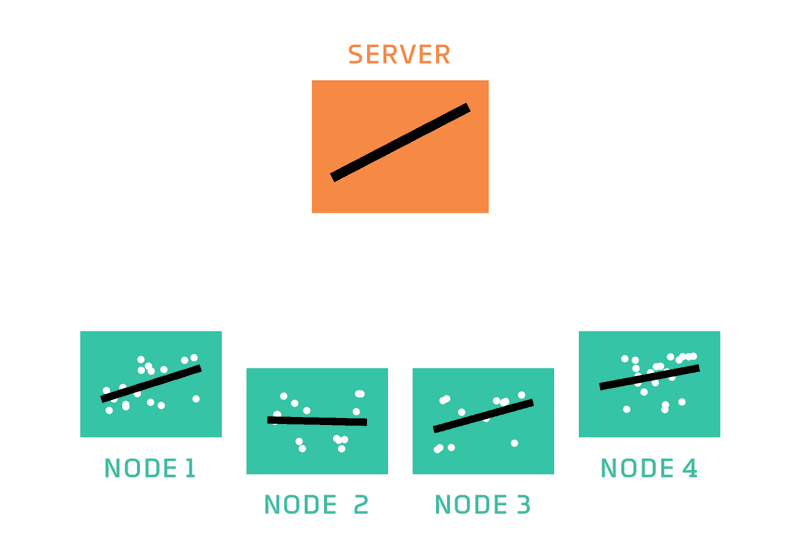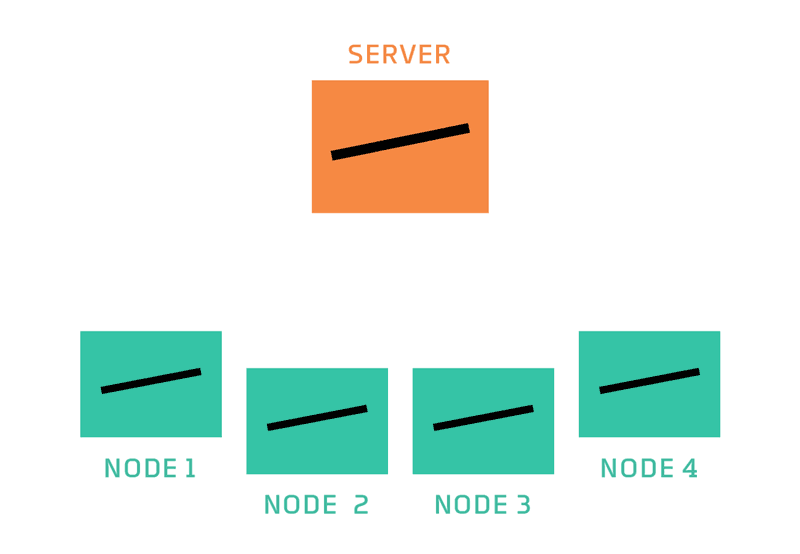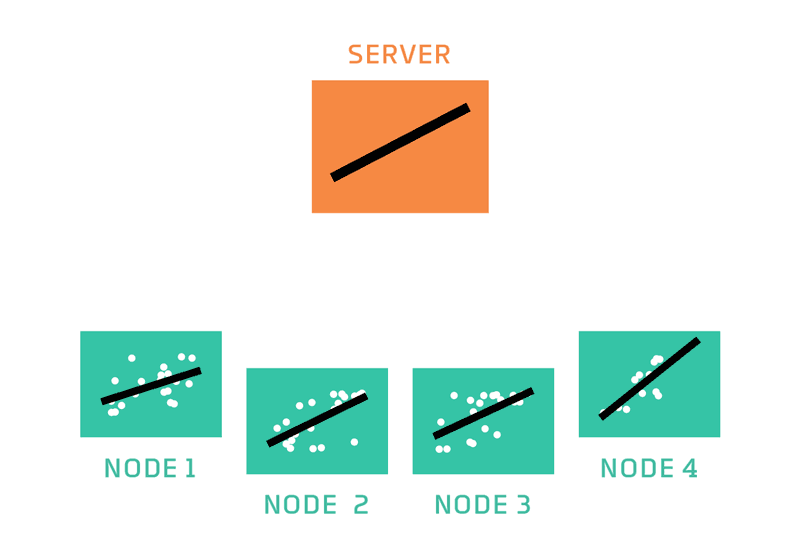
Image from here.
The standard process of federated learning was that proposed by McMahan and is called Federated Averaging. It is a fairly simple process that has a server orchestrating the training process and repeats the following steps until training is stopped:
- Client selection: The server samples from a set of clients meeting eligibility requirements. For example, mobile phones might only check in to the server if they are plugged in, on an unmetered wi-fi connection, and idle, in order to avoid impacting the user of the device.
- Broadcast: The selected clients download the current model weights and a training program from the server.
- Client computation: Each selected device locally computes an update to the model by executing the training program, which might for example run SGD on the local data.
- Aggregation: The server collects an aggregate of the device updates. For efficiency, stragglers might be dropped at this point once a sufficient number of devices have reported results. This stage is also the integration point for many other technique, possibly including: secure aggregation for added privacy, lossy compression of aggregates for communication efficiency, and noise addition and update clipping for differential privacy.
- Model update: The server locally updates the shared model based on the aggregated update computed from the clients that participated in the current round.
For a more illustrated description of federated learning, see this comic from Google.
Tools
The following are common tools used to implement federated learning in practice.
- TensorFlow Federated
- Federated AI Technology Enabler
- PySyft
- Leaf
- PaddleFL
- Clara Training Framework